
Video Esercitazione Pratitca n.1 – Database con Mysql
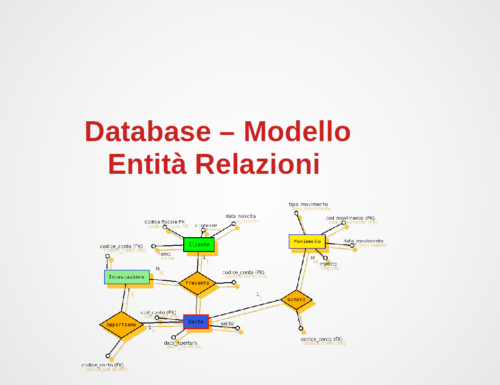
L’obiettivo di questa esercitazione pratica n.1 è quella di realizzare un Database a partire dalla sua progettazione concettuale,…
L'informatica professionale al vostro servizio !





Tema Seamless René, sviluppato da Altervista
Apri un sito e guadagna con Altervista - Disclaimer - Segnala abuso - Privacy Policy - Personalizza tracciamento pubblicitario