Basi di Dati – Lezione 1 – Modelli Logici e Fasi della progettazione
Indice dei contenuti
- Modello Logico
- Fasi della progettazione
- Classificazione dei Modelli Logici
- Modello Relazionale
- Caso di studio
1 – Modelli Logico
In informatica quando è necessario gestire una grande quantità di informazioni omogenee ovvero della stessa tipologia, come elenco delle persone di un comune, elenco dei libri di una biblioteca, ecc due sono le possibili modalità di gestione o con i file o con i database. La differenza nella realizzazione e risoluzione di problemi connessi alla gestione di enormi quanttià di dati risiede nel fatto che con la gestione con i file la velocità di esecuzione e di consultazione delle operazioni sui file sono molto più rapide che nella gestione con i database in quanto si sfruttano attraverso un linguaggio di programmazione istruzioni che agisocono direttamente sui dati, mentre con i database si passa attraverso un gestore chiamato DBMS. Per poter gestire le grandi quantità di dati nella prima modalità gli utenti devono saper programmare e realizzare quindi le procedure che gestiscono i dati. Invece nella gestione a livello di database l’utente deve conoscere al più ma non in modo obbligatorio un linguaggio semantico e informativo ovvero che svolge delle semplici operazioni sulle informazioni. Parlano di informazione e dati si deve però precisare una differenza.
Per dato si intende un fatto raccolto mediante osservazione diretta misurazione. Per informazione si intende una raccolta di dati che si riferiscono in modo univoco e non ambiguo ad un oggetto o ad un soggetto. Un aggregato di dati relativi ad un’informazione si chiama record logico e le sue componenti che possono essere di tipo diverso si chiamano campi. Un insieme di record logici possono essere memorizzate in una tabella che risiede in memoria centrale (vettore di record) oppure essere memorizzati su una memoria permanente come un’unità a disco e in questo caso si parla di file. Nella gestione a livello di programmazione il programma si deve interessare della memorizzazione dei dati sui supporti e quindi del passaggio da una struttura logica ad una fisica. Nella gestione mediante Database l’utente si disinteressa di questo passaggio occupandosi solo del livello logico del problema da risolvere. Inoltre nel primo caso l’utente si deve interessare anche dei meccanismo di accesso ai file da parte di più applicazioni e utenti andando incontro alle problematiche di condivisione dei file. Tutto questo se gestito dai database viene automaticamente soddisfatto dal DBMS.
La definizione di Database è pertanto una collezione di dati strutturati e organizzati alla quale accedono diversi utenti da differenti applicazioni.
Nella gestione a database la situazione che si presenta schematicamente può essere rappresentata dal diagramma sottostante.
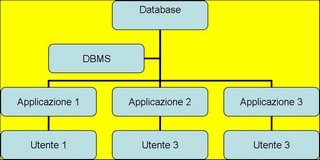
Nello schema si evidenzia il fatto che ogni utente interagisce con la base di dati tramite un’applicazione e tale applicazione passa le richieste dell’utente al DBMS che trasforma le richieste delle applicazioni di tipo logiche in operazioni di i/o tramite il sistema operativo sull’archivio fisico. In questo modo l’utente si disinteressa del tutto di quest’ultima gestione. Lo schema proposto non è l’unico possibile anche perché le applicazioni possono interagire fra di loro per scambiarsi dati. Tale scambio però avviene sempre passando attraverso il DBMS. Lo svantaggio di questo approccio risiede nel fatto che sull’elaboratore su cui girano le applicazioni deve essere presente il software di DBMS. Nella realizzazione invece di programmi diretti per la gestione degli archivi invece viene garantita una buona portabilità da elaboratori differenti a sistemi differenti mentre però la flessibilità ovvero la possibilità di modificare parte del programma comporta un grosso sforzo in termini d tempo e di ridefinizione delle strutture dati. Le peculiarità principali di un DBMS e quindi dei database che essi gestiscono sono:
- Garantisce l’integrità dei dati, la consistenza, e elimina la ridondanza degli stessi
- Gestisce in modo sicuro gli accessi contemporanei ai dati
- Gestisce le utenze in livelli di credenziali
- Permette all’utente di eliminare le ridondanze
- Facilità la gestione di archivi distribuiti
- Permette la realizzazione di basi dati relazionali
Per ridondanza si intende la duplicazione di dati in più parti dell’archivio ad esempio se si deve gestire l’archivio degli elettori di un comune in questo archivio possono essere presenti i dati anagrafici degli stessi che però sono anche ripetuti nell’archivio anagrafico del comune. Eliminare le ridondanze non significa però cancellare del tutto i dati duplicati ma tenere solo quelli strettamente necessari. Per eliminare queste ridondanze nel database si ricorre alla creazione di relazioni fra le grandezze informative in gioco. La consistenza è la caratteristica che garantisce ai dati che si propagano nelle varie grandezze informative di avere lo stesso valore. L’integrità nei database garantisce che i dati che sono inseriti all’inertno degli archivi sono coerenti ad esempio nell’inserimento di campi obbligatori e nel corretto formato degli stessi.
La gestione sicura dell’accesso ai dati riguarda la protezione dei dati. In generale non è possibile effettuare delle modifiche contemporanee ai dati e quindi il DBMS implementa dei meccanismi di protezione dell’accesso in scrittura sui dati inserendo durante un operazione di scrittura il bit di locking un valore che indica ad altre applicazione che vogliono nello stesso momento accedere agli stessi dati che è possibile effettuare solo operazioni di lettura.
La gestione degli utenti attraverso un sistema di credenziali indica diversi livelli di accesso al database infatti si definiscono gli utenti amministratori che creano e modificano i permessi degli utenti del livello inferiore, modificano le strutture dei dati, dei database nello specifico, effettuano operazioni di backup (copia di sicurezza), ecc.
Fasi di progettazione di un Database (Modellazione dei Dati)
Per poter progettare e realizzare concretamente un Database si deve prima realizzare la modellazione dei dati che si vuole gestire e poi scegliere un software DBMS che consenta di tradurre in procedure e applicativi la gestione e la realizzazione del modello proposto. All’uopo si deve dire che la modellazione dei dati passa attraverso tre passi:
- Progettazione concettuale o esterna in questa fase chi deve organizzare il database e realizzarlo esegue un’indagine sulle informazioni che dovrà contenere il database e quali saranno le funzioni richieste. In questa fase si deve avvalere della collaborazione dei lavoratori dell’azienda che decide di realizzare il database e di tutti i settori coinvolti. Il progettista organizza il modello secondo contenuti informativi e sceglie uno dei modelli concettuali, Di modelli concettuali ne esistono alcuni i più importanti sono il modello Entità-Relazioni,
- Progettazione logica in questa fase si deve decidere la realizzazione logica del modello concettuale creato in precedenza e si realizzano e si costruiscono le tabelle che conterranno le informazioni secondo i contenuti informativi descritti nella fase concettuale; Inoltre qui si definiscono le relazioni logiche fra i dati e i vincoli di integrità a cui essi devono soddisfare.La progettazione logica può prevedere anche l’aoozione di altri modelli quali il modello gerarchico, il modello reticolare e il modello a grafi che a breve illustreremo.
- Nella progettazione fisica si deicde la dislocazione della base di dati, la sua distribuibità e i supporti di memorizzazione richiesti.
Modelli Logici
In ogni modello è opportuno definire le grandezze informative in gioco e le relazione che intercorrono fra esse evidenziando anche il significato della relazione..
Modello Gerarchico
In questo modello si assegna una gerarchia alle grandezze informative in gioco organizzandola in una struttura ad albero in cui ogni grandezza informativa che chiameremo d’ora in poi entità può accedere alle informazioni dei livelli sottostanti ma non di quelle sopra di esse. Un esempio è rappresentato dallo schema sottostante.
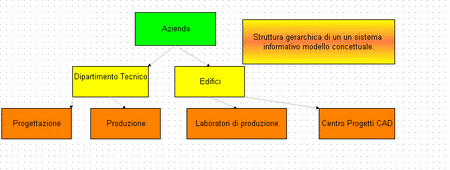
In questo esempio si vuole evidenziare l’organizzazione del patrimonio informativo di un’azienda. Ogni grandezza informativa ad esempio il Dipartimento Tecnico accede alle informazioni del settore Produzione e Progettazione ma non alle informazioni dell’Azienda (livello superiore potrebbero essere i dati sulle vendite, sul personale ecc.). In questo modo le applicazioni e il Database che ne scaturisce da questo modello sarà molto vincolato alla non comunicazione ( o non accesso) alle informazioni dei livelli superiori.
Modello a grafo
In questo modello logico le informazioni sono collegate attraverso delle relazioni di dipendenza con percorso obbligato. In altri termini le informazioni sono organizzate in strutture a lista dove ciascun elemento può accedere all’elemento precedente e successivo della lista ma non a quello di altra lista. Tale modello si presta bene per la realizzazioni di viste specifiche sui dati. Un esempio è riportato nello schema sottostante.
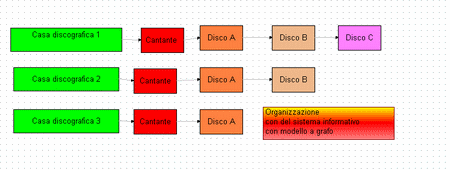
In questo esempio si vogliono organizzare le informazioni relative ai cantanti e ai loro dischi con un criterio di raggruppamento dei cantanti per casa discografica. Ogni rettangolo rappresentano dati sulle case discografiche, i loro cantanti e i dischi che hanno inciso e quindi venduto. In questo modello a grafo la casa discografica consulta i dati dei cantanti e dei loro dischi secondo una struttura a lista ovvero una volta scelto un cantante potrò visualizzare solo i dati dei dischi che esso ha prodotto.
Modello Relazionale
Puoi abbonarti al link al menù principale o cliccando sul link Abbonati Ora!